长沙一业主自管小区竟比物业干得好,还给业主发了68万红包
2023-11-05
更新时间:2023-10-31 16:05:17作者:橙橘网
白交 发自 凹非寺
量子位 | 公众号 QbitAI
突然间,整个大模型圈都在谈论同一件事。
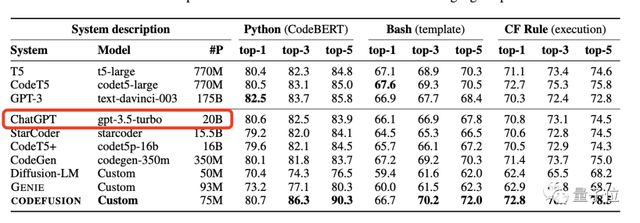
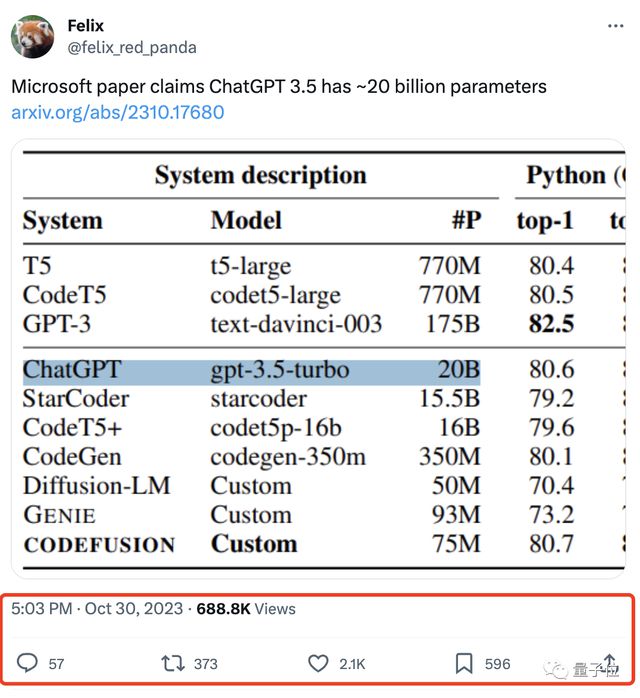
微软论文里一张「乍一看不足为奇」的统计图,泄露了“天机”。
引领全球风暴的ChatGPT,背后大模型参数竟只有200亿???
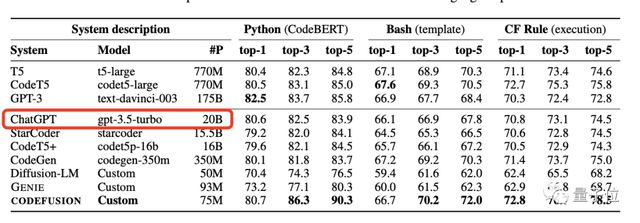
论文一经发布,就吸引了国内外众多关注。


不少网友还不相信:确定不是拼写错了?
有网友表示:难怪OpenAI对开源这么紧张。又或者,这也许是为OpenAI开源做准备。

无独有偶,就在前几天有网友在GitHub Copilot的API中发现了疑似GPT-4新型号:copilot-gpt-4-2,所拥有的知识更新到了2023年3月。

这篇论文说了啥?
除了泄露机密,这篇论文本身也值得一看:业内首个用扩散模型做代码生成。
研究团队设想了这样一个场景:
用自然语言生成代码的自回归模型也有类似的局限性:不太容易重新考虑之前生成的tokens。

微软研究员提出了采用编码-解码架构的CODEFUSION,主要包括编码器、解码器、去噪器以及Classification Head,将自然语言输入编码为连续表示,然后将其附加条件输入Diffusion模型中用高斯噪声进行迭代去噪。
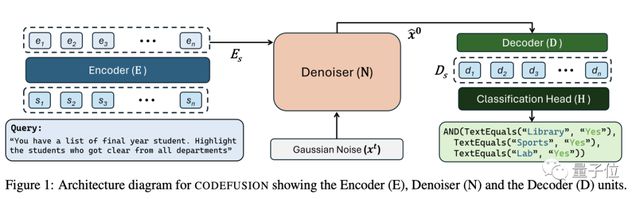
为了生成语法正确的代码,去噪后输入解码器中获得代码tokens,通过针对代码的连续段落去噪(CPD)任务预训练CODEFUSION。
在Python、Bash和Excel条件格式化(CF)规则三个语言任务上评估了CODEFUSION。
结果显示其7500万参数规模CODEFUSION性能,同200亿参数的GPT-3.5-turbo接近,而且还生成更加多样化的代码。
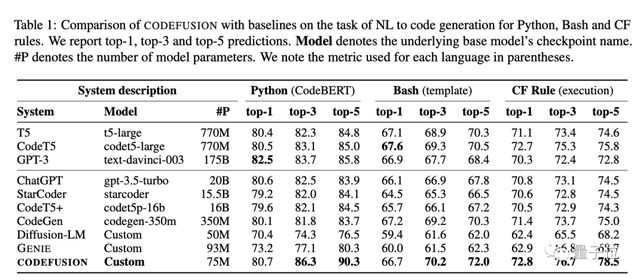
与纯文本生成的diffusion模型相比,CODEFUSION生成更多语法正确的代码;与自动回归模型相比,生成更加多样化的候选代码。
与最先进的自回归系统(350M-175B 参数)相比,在前 1 名的准确率方面表现相当,而在前 3 名和前 5 名的准确率方面,由于其在多样性与质量之间取得了更好的平衡,其表现优于自回归系统。
结果这原本只是一次再正常不过的性能比较,没想到引起轩然大波。
也有人开始了阴谋论,或许这是OpenAI开源的“前菜”,故意而为之——
因为不少大模型已经追赶上来了,而且早在今年5月,路透社就曾爆料OpenAI准备开源新大语言模型。

One More Thing
值得一提的是,早在今年2月份福布斯一则新闻报道里,就曾透露过ChatGPT只有200亿参数。

当时标题是「越大越好吗?为什么 ChatGPT VS GPT-3 VS GPT-4 的 “战斗 “只是一次家庭聊天?」
只是当时没有太多人在意。
参考链接:
[1]https://twitter.com/felix_red_panda/status/1718916631512949248
[2]https://x.com/teortaxesTex/status/1718972447024623898?s=20
[3]https://www.reddit.com/r/singularity/comments/17jrepb/microsoft_paper_claims_chatgpt_35_has_20_billion/
[4]https://www.zhihu.com/question/628395521
[5]https://www.reddit.com/r/ChatGPT/comments/17ht56t/new_leaks_about_upcoming_developments_with_openai/?share_id=txV27HR0zw0TjV8dLXf4l
[6]https://www.forbes.com/sites/forbestechcouncil/2023/02/17/is-bigger-better-why-the-chatgpt-vs-gpt-3-vs-gpt-4-battle-is-just-a-family-chat/amp/