潍坊坊子区赶集时间及地点
2023-12-09
更新时间:2023-12-09 16:05:18作者:橙橘网

IT之家 12 月 9 日消息,据彭博社、Tom's Hartware 等外媒当地时间周五报道,谷歌发言人在采访中承认,前段时间谷歌发布的大语言模型 Gemini 演示视频并非实时录制。
乍看之下,这个一镜到底的视频中,Gemini 模型可发现藏在指定塑料杯内的纸团,或者看出一张“连点成线”的图片画的是螃蟹。但是,谷歌发言人告诉彭博社,这段演示视频是利用镜头中的静止图像帧和文字提示“拼凑”而成的,Gemini 只能对输入的提示和静态图像做出反应。同样,视频中用户与 Gemini 的语音互动也由后期配音完成。

至于视频中的人物说话、绘画、展示物品乃至魔术,似乎也只是为了演示视频而特意安排的。在谷歌官方 YouTube 频道中,谷歌也添加了描述称“为了演示的目的,延迟已经减少,Gemini 的输出也缩短了,以求简洁”。这意味着 Gemini 每次响应所需的时间实际上要长于视频的演示。
此外,谷歌 DeepMind 研究副总裁兼深度学习负责人 Oriol Vinyals 也对这段视频做进一步解释:这段视频展示的是使用 Gemini 构建的多模态用户体验“可能的样子”,是为了激发开发人员的灵感。其称,视频中的所有用户提示和输出都是真实的,为简洁起见进行了缩短。而且,视频中展示的模型为 Gemini Ultra。
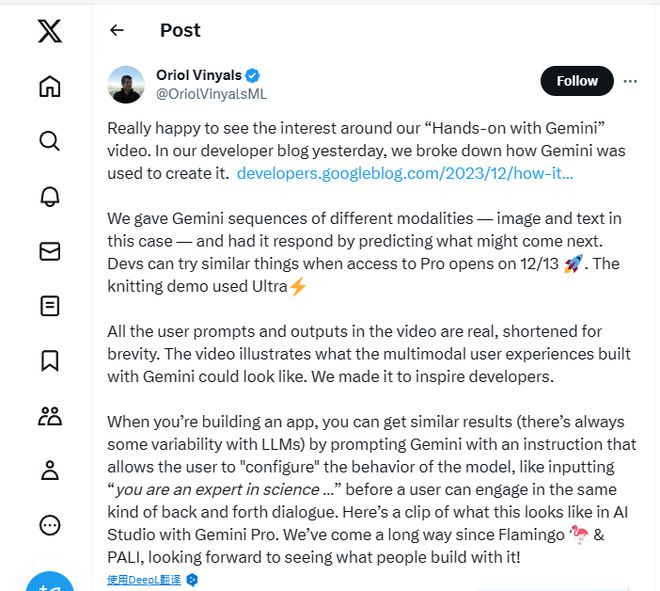
据IT之家此前报道,谷歌曾声称 Gemini Ultra 的性能在 32 个广泛使用的学术基准测试中有 30 个都表现出了超越当前时代的“先进结果”,而这些基准测试也是当前 LLM 领域最常用、最泛用的测试。
其中,它以 90.0% 的得分成为第一个在 MMLU(大规模多任务语言理解)上超越人类专家的模型(该测试结合了数学、物理、历史、法律、医学和伦理等 57 个学科)。
Gemini Ultra 还在新的 MMMU 基准测试上表现出了 59.4% 的领先级性能,该测试涵盖了“需要深思熟虑的”不同领域的多模态任务。
明年初,谷歌还将推出全新升级的Bard Advanced,让用户可以更好地体验到其最好的模型和功能,也就是 Gemini Ultra。