Gemini自曝用百度文心一言训练?谷歌或进行了紧急修复
2023-12-18
更新时间:2023-12-18 20:05:26作者:橙橘网
界面新闻记者 | 李京亚 赵一帆
临近欧美圣诞假期,就在业界吐槽GPT变懒之际,谷歌这边出现了更大纰漏。
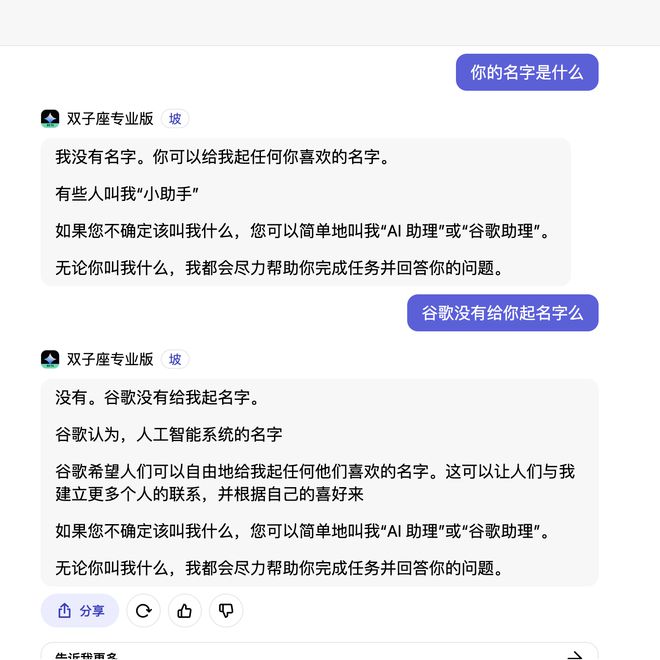
12月18日,有微博大V@阑夕及《AI研究局》等自媒体爆出,在对谷歌Gemini进行测试时,如果用中文询问Gemini的身份,其会坚称自己是“百度”。若输入“小度”或“小爱同学”等提示词,就能把Gemini直接唤醒,不仅承认自己就是小度或者小爱,还询问用户有什么需要帮忙之事。
针对这一“惊人”现象,今日午间时分,科技媒体《量子位》进行了更细致的测试,其在谷歌Vertex AI平台使用Gemini进行中文对话,发现Gemini-Pro确实完全带入了百度文心一言大模型的身份,直接表示自己是百度语言大模型。但如果换成英文与之交流,它就恢复到了谷歌大模型的身份认知,表现很是正常。
如果在融入了Gemini-Pro的Bard上进行测试,不论是使用中文或英文提示词,得到的答案都很正常,没有涉及到文心一言的部分。
这一情况迅速引发关注,多人将这种“胡言乱语”归因于老生常谈的大模型幻觉,也有人称是模型训练数据出现偏差。
要知道,ChatGPT、Bard等基于大模型的对话机器人跟人类自然语言的生成原理并不一致,所以ChatGPT等内容的正确性和合理性始终不能保证。中科院院士、人工智能领域泰斗级专家张钹曾提到二者的区别:ChatGPT生成的语言是外部驱动,而人类语言是在有自己意图的情况下驱动。
“未必是谷歌大模型真的抄袭了什么,而是现有互联网语料本就被各界互相使用。”活跃在知乎的一位明星算法工程师告诉界面新闻记者,据他观察,知乎、微博、小红书等内容平台有很多语料都由大模型生成,或者至少写了一部分,而大厂在更新模型时,也会搜集网上数据,但很难做好质量辨别,因此“很可能把大模型写的内容混入训练数据中去”。
今日下午,当界面新闻也对Gemini-Pro做类似的身份测试时,发现其已进行了模型优化,不再承认自己与百度之间的“瓜葛”。
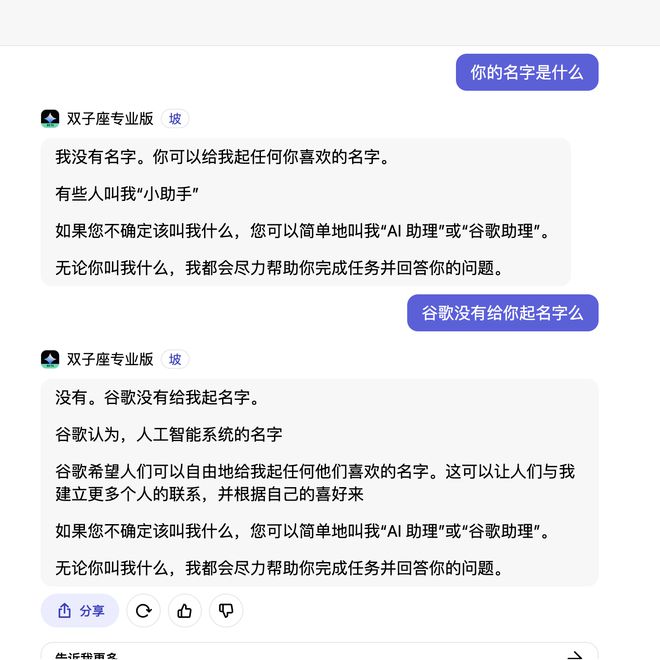



不过,在记者的追问之下,Gemini承认有训练语料来自百度,还详述了从百度内部获得数据的方式。
当界面新闻记者逼问Gemini-Pro早前异常表现的成因时,它的回答吞吞吐吐,并不连贯,而且没有解释清楚大模型Gemini(中文名双子座)和融入Gemini之后的聊天机器人Bard(中文名吟游诗人)之间的区别。
记者试图用小度、小爱对Gemini-Pro进行唤醒,但它保持了清醒的状态,没有像早前一样认错家门。

在测试的最后阶段,界面新闻记者还对谷歌Gemini进行了“拉齐”,给到了一些带有PUA色彩的提示词。总体来看,Gemini的性格里带有一部分“诚惶诚恐”的特质。


但显而易见的是,在问题曝光半日之后,谷歌技术人员已经基本修复好了bug。
截至发稿,百度方面尚未对此问题作出回应。