汴北安置区四期住宅上房公告
2023-12-02
更新时间:2023-11-06 22:05:28作者:橙橘网

机器之心报道
机器之心编辑部
李开复表示,「零一万物要跻身全球大模型第一梯队。」

开源大模型宇宙又有了新的重量级成员,这次是创新工场董事长兼 CE0 李开复大模型公司「零一万物」推出的「Yi」系列开源大模型。据悉,零一万物在今年 3 月底官宣成立,六七月开始运营,李开复博士为创始人兼 CEO。
11 月 6 日,零一万物正式发布「Yi」系列预训练开源大模型,包括了Yi-6B 和 Yi-34B 两个版本,给了开源大模型社区「一点小小的震撼」。
根据 Hugging Face 英文开源社区平台和 C-Eval 中文评测的最新榜单,Yi-34B 预训练模型取得了多项 SOTA 国际最佳性能指标认可,成为全球开源大模型「双料冠军」,击败了 LLaMA2 和 Falcon 等开源竞品。

Yi-34B 也成为迄今为止唯一成功登顶 Hugging Face 全球开源模型排行榜的国产模型。

以小博大,登顶全球英文及中文权威大模型榜单No 1
我们了解到,在 Hugging Face 英文测试公开榜单 Pretrained 预训练开源模型排名中,Yi-34B 的各项指标表现亮眼,以 70.72 的分数位列全球第一,以小博大,碾压 LLaMA2-70B 和 Falcon-180B 等众多大尺寸模型。
在参数量和性能方面,Yi-34B 相当于只用了不及 LLaMA2-70B 一半、Falcon-180B 五分之一的参数量,取得了在各项测试任务中超越全球领跑者的成绩。凭借出色表现,Yi-34B 跻身目前世界范围内开源最强基础模型之列。

来源:
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
同时作为国产大模型, 李开复表示,Yi-34B 更「懂」中文,在 C-Eval 中文权威榜单排行榜上超越了全球所有开源模型。
相较于大模型最强王者 GPT-4,Yi-34B 在 CMMLU、E-Eval、Gaokao 三个主要中文指标上具有绝对优势,凸显中文世界的优异能力,能够更好地满足国内市场需求。

从更为全面的评估看,在全球大模型各项评测中最关键的「MMLU」(Massive Multitask Language Understanding,大规模多任务语言理解)、BBH 等反映模型综合能力的评测集上,Yi-34B 表现最为突出,在通用能力、知识推理、阅读理解等多项指标评比中全部胜出,与 Hugging Face 评测高度一致。
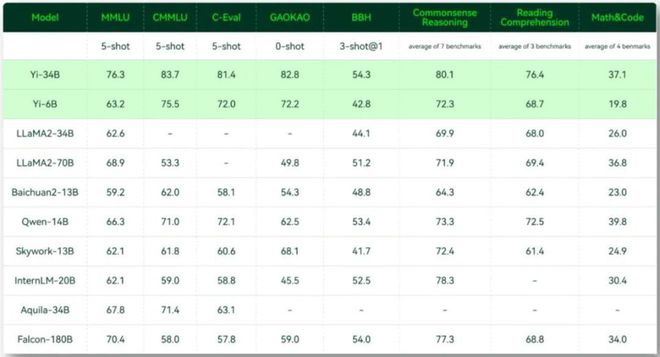
不过,与 LLaMA2 一样,Yi 系列开源大模型在 GSM8k、MBPP 的数学和代码评测表现略逊 GPT 模型。未来,Yi 系列大模型将推出专攻代码能力和数学能力的继续训练模型。
上下文窗口大小突破 200k,并直接开源
在对大模型实战效果至关重要的上下文窗口方面,此次开源的 Yi-34B 发布了全球最长、支持 200K 超长上下文窗口版本,可以处理约 40 万汉字超长文本输入,大致相当于一本《儒林外史》的长度。相比之下,OpenAI 的 GPT-4 上下文窗口只有 32K,文字处理量约 2.5 万字。

如何做到的呢?据了解,零一万物技术团队实施了一系列优化,包括了计算通信重叠、序列并行、通信压缩等。通过这些能力增强,实现了在大规模模型训练中近 100 倍的能力提升。
值得一提的是,零一万物还是第一家将超长上下文窗口开源开放的大模型公司,允许开发者直接使用。
Yi-34B 的 200K 上下文窗口直接开源,不仅能提供更丰富的语义信息,理解超过 1000 页的 PDF 文档,让很多依赖于向量数据库构建外部知识库的场景都可以用上下文窗口来进行替代。Yi-34B 的开源属性也给想要在更长上下文窗口进行微调的开发者提供了更多的可能性。
独有科学训模方法,训练成本下降 40%
Yi-34B 如此强大,这要得益于以下两个关键因素,即AI Infra 团队、自研规模化训练平台。
李开复介绍称,零一万物内部设立了 AI Infra(AI Infrastructure)团队,主要负责大模型训练和部署提供各种底层技术设施,包括处理器、操作系统、存储系统、网络基础设施、云计算平台等等,成为 Yi 系列模型训练背后极其关键的「保障技术」。
凭借强大的 AI Infra 支撑,零一万物团队实现了超越行业水平的训练效果。Yi-34B 模型训练成本实测下降 40%,实际训练完成达标时间与预测的时间误差不到一小时,进一步模拟上到千亿规模训练成本可下降多达 50%。
与此同时,零一万物实现了从「粗放炼丹」到「科学训模」方法论的转化。
经过几个月的建模和实验,零一万物自研出一套「规模化训练实验平台」,用来指导模型的设计和优化。数据配比、超参搜索、模型结构实验都可以在小规模实验平台上进行,对 34B 模型每个节点的预测误差都可以控制在 0.5% 以内。模型预测能力更强,大大减少了进行对比实验需要的资源,也减少了训练误差对于计算资源的浪费。
数据处理管线和加大规模预测的训练能力建设,把以往的大模型训练碰运气的「炼丹」过程变得极度细致和科学化,不仅保证了目前发布 Yi-34B、Yi-6B 模型的高性能,也为未来更大规模模型的训练压缩了时间和成本,还有能力以领先于行业的速度将模型规模扩大到数倍。
最后,李开复也宣布,在完成 Yi-34B 预训练的同时,已经旋即启动下一个千亿参数模型的训练。

未来几个月,我们预计将看到更多的 Yi 后续大模型亮相。